正则表达式是由字符构成的表达式,每个字符代表一个规则,表达式中的字符分为两种类型:普通字符和元字符。普通字符是指字面含义不变的字符,按照完全匹配的方式匹配文本,而元字符具有特殊的含义,代表一类字符。
把文本看作是字符流,每个字符放在一个位置上,例如,正则表达式 “Room\d\d\d”,前面四个字符Room是普通字符,后面的字符\是转义字符,和后面的字符d组成一个元字符\d,表示该位置上有任意一个数字。
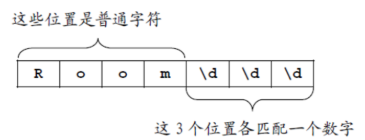
用正则表达式的语言来描述是:正则表达式 “Room\d\d\d”共捕获7个字符,表示“以Room开头、以三个数字结尾”的一类字符串,我们把这一类字符串称作一个模式(Pattern),也称作是一个正则。
1.转义字符
转义字符是\,把普通字符转义为具有特殊含义的元字符,常用的转义字符有:
|
1 2 3 4 5 6 |
\t:水平制表符 \v:垂直制表符 \r:回车 \n:换行 \\:表示字符 \,也就说,把转义字符 \ 转义为普通的字符 \ \":表示字符 ",在C#中,双引号用于定义字符串,字符串包含的双引号用 \" 来表示 |
2.字符类
在进行正则匹配时,把输入文本看作是有顺序的字符流,字符类元字符匹配的对象是字符,并会捕获字符。所谓捕获字符是指,一个元字符捕获的字符,不会被其他元字符匹配,后续的元字符只能从剩下的文本中重新匹配。
|
1 2 3 4 5 6 7 8 9 10 11 |
[ char_group]:匹配字符组中的任意一个字符 [^char_group]:匹配除字符组之外的任意一个字符 [first-last]:匹配从first到last的字符范围中的任意一个字符,字符范围包括first和last。 . :通配符,匹配除\n之外的任意一个字符 \w:匹配任意一个单词(word)字符,单词字符通常是指A-Z、a-z和0-9 \W:匹配任意一个非单词字符,是指除A-Z、a-z和0-9之外的字符 \s:匹配任意一个空白字符 \S:匹配任意一个非空白字符 \d:匹配任意一个数字字符 \D:匹配任意一个非数字字符 x|y 匹配x或y。例如,‘z|food’能匹配“z”或“food”。‘(z|f)ood’则匹配“zood”或“food” |
注意,转义字符也属于字符类元字符,在进行正则匹配时,也会捕获字符。
3.定位符
定位符匹配(或捕获)的对象是位置,它根据字符的位置来判断模式匹配是否成功,定位符不会捕获字符,是零宽的(宽度为0),常用的定位符有:
|
1 2 3 4 5 6 7 8 |
^:默认情况下,匹配字符串的开始位置;在多行模式下,匹配每行的开始位置; $:默认情况下,匹配字符串的结束位置,或 字符串结尾的\n之前的位置;在多行模式下,匹配每行结束之前的位置,或者每行结尾的\n之前的位置。 \A:匹配字符串的开始位置; \Z:匹配字符串的结束位置,或 字符串结尾的\n之前的位置; \z:匹配字符串的结束位置; \G:匹配上一个匹配结束的位置; \b:匹配一个单词的开始或结束的位置; \B:匹配一个单词的中间位置; |
4.量词、贪婪和懒惰
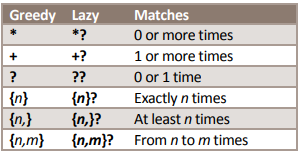
量词是指限定前面的一个正则出现的次数,量词分为两种模式:贪婪模式和懒惰模式,贪婪模式是指匹配尽可能多的字符,而懒惰模式是指匹配尽可能少的字符。默认情况下,量词处于贪婪模式,在量词的后面加上?来启用懒惰模式。
|
1 2 3 4 5 6 |
*:出现0次或多次 +:出现1次或多次 ?:出现0次或1次 {n}:出现n次 {n,}:出现至少n次 {n,m}:出现n到m次 |
注意,出现多次是指前面的元字符出现多次,例如,\d{2} 等价于 \d\d,只是出现两个数字,并不要求两个数字是相同的。要表示相同的两个数字,必须使用分组来实现。
5.分组和捕获字符
() 括号不仅确定表达式的范围,还创建分组,()内的表达式就是一个分组,引用分组表示两个分组匹配的文本是完全相同的。定义一个分组的基本语法:
|
1 |
(pattern) 匹配 pattern 并获取这一匹配 |
该类型的分组会捕获字符,所谓捕获字符是指:一个元字符捕获的字符,不会被其他元字符匹配,后续的元字符只能从剩下的文本中重新匹配。
分组编号和命名
默认情况下,每个分组自动分配一个组号,规则是:从左向右,按分组左括号的出现顺序进行编号,第一个分组的组号为1,第二个为2,以此类推。也可以为分组指定名称,该分组称作命名分组,命名分组也会被自动编号,编号从1开始,逐个加1,为分组指定名称的语法是:
|
1 |
(?< name > pattern) |
通常来说,分组分为命名分组和编号分组,引用分组的方式有:
- 通过分组名称来引用分组:\\
- 通过分组编号来引用分组:\number
注意,分组只能后向引用,也就是说,从正则表达式文本的左边开始,分组必须先定义,然后才能在定义之后面引用。
在正则表达式里引用分组的语法为“\number”,比如“\1”代表与分组1 匹配的子串,“\2”代表与分组2 匹配的字串,以此类推。
例如,对于 "<(.*?)>.*?</\1>" 可以匹配 <h2>valid</h2>,在引用分组时,分组对应的文本是完全相同的。
分组构造器
|
1 2 3 4 |
(pattern):捕获匹配的子表达式,并为分组分配一个组号 (?< name > pattern):把匹配的子表达式捕获到命名的分组中 (?:pattern):非捕获的分组,并未分组分配一个组号(仍会匹配,但不会分配组号) (?> pattern):贪婪分组 |
贪婪分组也称作非回溯分组,该分组禁用了回溯,正则表达式引擎将尽可能多地匹配输入文本中的字符。如果无法进行进一步的匹配,则不会回溯尝试进行其他模式匹配。
6.零宽断言
零宽:
指的是它们不与任何字符相匹配,而匹配一个位置。
断言:
指的是一个判断,正则表达式中只有当断言为真时才会继续进行匹配。
正则表达式把文本看作从左向右的字符流,向右叫做后向(Look behind),向左叫做前向(Look ahead)。对于正则表达式,只有当匹配到指定的模式(Pattern)时,断言为True,叫做肯定式,把不匹配模式为True,叫做否定式。
|
1 2 3 4 |
(?= pattern):前向、肯定断言 (?! pattern):前向、否定断言 (?<= pattern):后向、肯定断言 (?<! pattern):后向、否定断言 |
前向肯定断言
前向肯定断言定义一个模式必须存在于文本的末尾(或右侧),但是该模式匹配的子串不会出现在匹配的结果中,前向断言通常出现在正则表达式的右侧,表示文本的右侧必须满足特定的模式。
举个例子:
|
1 |
\b\w+(?=\sis\b) |
对正则表达式进行分析:
- \b:表示单词的边界
- \w+:表示单词至少出现一次
- (?=\sis\b):前向肯定断言,\s 表示一个空白字符, is 是普通字符,完全匹配,\b 是单词的边界。
从分析中,可以得出,匹配该正则表达式的文本中必须包含 is 单词,is是一个单独的单词,不是某一个单词的一个部分。
|
1 |
Sunday is a weekend day 匹配该正则,匹配的值是Sunday,而The island has beautiful birds 不匹配该正则。 |
后向肯定断言
后向肯定断言定义一个模式必须存在于文本的开始(或左侧),但是该模式匹配的子串不会出现在匹配的结果中,后向断言通常出现在正则表达式的左侧,表示文本的左侧必须满足特定的模式。
还是举个例子
|
1 |
(?<=\b20)\d{2}\b |
对正则表达式进行分析:
- (?<=\b20):后向断言,\b表示单词的开始,20是普通字符
- \d{2}:表示两个数字,数字不要求相同
- \b:单词的边界
该正则表达式匹配的文本具备的模式是:文本以20开头、以两个数字结尾。
